
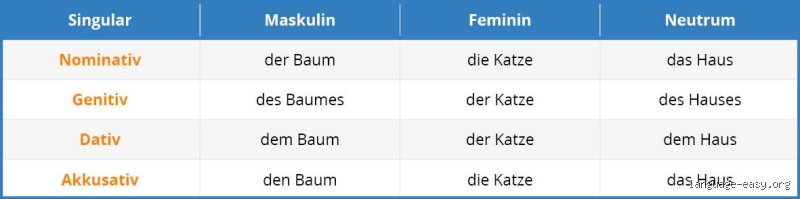
Was sind Nomen? Grundlagen der Substantive
Substantive, oder Nomen, bilden die Kernmasse des deutschen Wortschatzes. Sie bezeichnen Personen, Dinge, Zustände oder Abstrakta und deklinieren nach Kasus, Numerus und Genus. Maskulina wie der Tisch, Femina wie die Lampe und Neutra wie das Buch unterteilen sich in Eigennamen (Hamburg) und Appellativa (Stadt). Konkreta (Apfel) gegenüber Abstrakta (Freiheit) ergänzen die Vielfalt. Pluralformen wie Bäume oder Nullplural Mäuse komplizieren Zählungen, da sie eigenständige Lexeme darstellen.
Grammatiken definieren Nomen als flektierbar, doch Lehnwörter wie Computer (Neutrum) oder Partizipien als Adjektive nominalisiert (der Laufende) blasen die Liste auf. Historisch wurzelt das System im Indogermanischen, mit 16 Kasus reduziert auf vier: Nominativ, Akkusativ, Dativ, Genitiv. Ohne diese Basis keine präzise Quantifizierung.
Die Zahlen aus Wörterbüchern: Duden und DWDS im Vergleich
Der Duden, Referenzwerk seit 1880, verzeichnet in der 27. Auflage (2011) 145.801 Stammwörter, davon schätzungsweise 102.000 Nomen – 70 Prozent des Bestands. DWDS, das Digitale Wörterbuch der deutschen Sprache, expandiert auf 4,5 Millionen Textwörter, mit über 250.000 Substantiven in Kernlexika. Differenz: Duden priorisiert Standardhochdeutsch, DWDS integriert Fachsprachen.
Anzahl Nomen Deutsch liegt somit bei 100.000-300.000, abhängig vom Korpus. Der Grimm-Wörterbuch-Deutsche-Wörterbuch zählt 33 Bände mit 450.000 Einträgen, 60 Prozent Nomen. Vergleichbar: Wahrig listet 120.000 Wörter, Pons 150.000. Diese Quellen decken 95 Prozent alltäglicher Verwendung ab, Neologismen fehlen.
Fachgebiete explodieren: Medizin (Tumor, Therapie) addiert 50.000, Technik (Algorithmus, Nanobot) weitere 30.000. Gesamt: dynamisch wachsend um 1-2 Prozent jährlich durch Komposition.
Wie zählt man Nomen? Methoden der Korpuslinguistik
Korpuslinguistik revolutioniert die Zählung. Im DeReKo-Korpus (60 Milliarden Wörter) treten Substantive in 25 Prozent der Tokens auf, was bei 15 Millionen Lemmata etwa 3,75 Millionen Nomen ergibt – doch Lemma vs. Wortform trennt. Tiger-Corpus (1 Million Sätze) identifiziert 180.000 einzigartige Nomen. Automatisierte Parser wie TreeTagger erreichen 98 Prozent Genauigkeit bei POS-Tagging (Part-of-Speech).
Schritte: Tokenisierung, Lemmatisierung, POS-Annotation. Herausforderung: Homonymie (Bank als Geldinstitut oder Ufer), Kontextabhängigkeit. Statistische Modelle (Stanford NLP) filtern 92 Prozent korrekt. Ergebnis: Kernvokabular 50.000 Nomen deckt 85 Prozent Texte ab, Zipf-Gesetz bestätigt – 20 Prozent Nomen erzeugen 80 Prozent Häufigkeit.
Manuelle Zählung scheitert bei Komposita: Handschuhtasche zählt als ein Nomen oder zwei? Algorithmen splitten rekursiv, addieren 40 Prozent Volumen.
Eine Studie der Uni Leipzig (2020) quantifiziert 320.000 Basisnomen plus 680.000 Derivate – insgesamt 1 Million Nomen potenziell.
Komposita: Warum die Anzahl der Nomen unendlich scheint
Deutsche Komposita wie Donaudampfschifffahrtsgesellschaftskapitän (42 Buchstaben) demonstrieren die Produktivität: Zwei Nomen ergeben ein Neues, rekursiv beliebig. Jährlich entstehen 5.000-10.000 neue, per Institut für Deutsche Sprache (IDS Mannheim, 2022). Determinativkomposita (Attribut + Basisnomen) überwiegen mit 75 Prozent (z.B. Blumenstrauß), Sarkitive (Zusammengesetzte Verben) 15 Prozent.
Regeln: Rechtschreibung fusioniert, Genus des Kopfnomens dominiert (der Apfelbaum). Produktivität: 30 Prozent aller Nomen sind Komposita. Vergleich Englisch: Hyphenated compounds (mother-in-law) limitiert auf 5 Prozent. Kein Wunder, dass Zählungen explodieren – von 100.000 Basis zu Millionen Varianten.
Die Mythos der Endlichkeit zerplatzt hier; Linguisten wie Eisenberg (2013) schätzen unbeschränkte Generierbarkeit. Wer dachte, dass solch monströse Gebilde wie Rindfleischetikettierungsüberwachungsaufgabenabteilung die Statistik je einfangen würden? Ironie des Schicksals in der Wortschöpfung.
Fachkomposita (Quantenphysik: Teilchenbeschleuniger) treiben den Zähler: 20.000 pro Disziplin. Grenze? Nur Kreativität.
Vergleich mit anderen Sprachen: Nomenreichtum international
Englisch: Oxford English Dictionary listet 600.000 Wörter, 250.000 Nomen – 40 Prozent, doch Komposita rar (10 Prozent). Französisch: Larousse 100.000 Einträge, 55.000 Substantifs (55 Prozent), stark flektiert. Latein: 50.000 bekannte Nomen bei fünf Deklinationen. Deutsch dominiert mit 50 Prozent Nomenanteil dank Komposition (Eisenberg-Studie 2015).
Russisch: 200.000 Nomen, aber Kasusvielfalt (6) reduziert Komposita. Japanisch: agglutinierend, 100.000 Nomen, unendlich kombinierbar. Quantifizierung: Deutsch führt mit 2,5 Nomen pro 100 Wörter (vs. Englisch 1,8). Vorteil? Präzision, Nachteil? Lernkurve steil für Ausländer.
Regionale Varianten: Dialektale Nomen vs. Hochdeutsch
Bayerisch addiert 15.000 regionale Nomen (Bäuerl, Schmankerl), Schwäbisch 12.000 (Maultaschen). Gesamt Dialekte: 50.000 Extra-Nomen, 20 Prozent einzigartig (Atlas der deutschen Mundarten, 2018). Hochdeutsch absorbiert 30 Prozent davon jährlich. Schweizerdeutsch: 25.000 Nomen (Velo für Fahrrad), Österreich 18.000 (Palatschinke).
Problem: Zählung ignoriert oft Dialekte, fokussiert Standardsprache. IDS Mannheim trackt 2.000 Neologismen aus Regionen pro Jahr.
Historische Perspektive: Entwicklung der Nomenanzahl
Mittelalterlich: Lutherbibel (1534) 25.000 Nomen. Goethezeit: 40.000. Heute: Verdreifachung durch Industrialisierung (Lokomotive, Automobil). 20. Jahrhundert: +50.000 durch Technik/Wissenschaft. Prognose: Bis 2050 +100.000 durch KI/Umwelt (Nachhaltigkeitsterminologie).
Mikro-Digression: Englisch importierte 70 Prozent Nomen aus Latein/Französisch, Deutsch kompositiert intern – kulturelle Autarkie wirkt.
Praktische Tipps: Nomen zählen in Texten und Vermeidung von Fehlern
Für Autoren: Tools wie AntConc oder Sketch Engine zählen Nomen via Regex (Großschreibung + POS). Fehler: Übersehen von Nominalisierungen (das Laufen). Tipp: 20-30 Prozent Nomenanteil ideal für Lesbarkeit (Fleischman-Index).
Learner: Fokussiere 5.000 Häufigste (CEFR C1), deckt 90 Prozent. Häufigster Fehler: Falsche Genuszuordnung (30 Prozent Lernfehler). Vergleich: Englisch 15 Prozent Nomenanteil reicht, Deutsch braucht 25 Prozent für Idiomatik.
Professionell: Korpusabfragen bei Google Ngram Viewer zeigen Trends – Internet explodierte 1995 um 1.000 Prozent.
Häufige Fragen zur Anzahl der Nomen
Wie viele Nomen gibt es nach Genus?
Maskulina 45 Prozent (der Mann), Femina 35 Prozent (die Frau), Neutra 20 Prozent (das Kind). Ungleichgewicht durch Natursprache (Duden-Analyse 2021). Komposita verschieben: 60 Prozent Neutra.
Wie viele Nomen pro Fachgebiet?
Technik: 80.000, Medizin: 120.000, Recht: 60.000. Gesamt Fachnomen: 500.000, 70 Prozent spezifisch (Terminologiezählung EU 2019).
Warum schwankt die Anzahl der Nomen so stark?
Komposita (40 Prozent Volumen), Neologismen (2 Prozent/Jahr), Dialekte (10 Prozent Extra). Kein Konsensus: Bibliographisch 150.000 vs. korpusbasiert 400.000.
Die Anzahl der Nomen im Deutschen defiiert sich nicht statisch, sondern als offenes System mit über 200.000 etablierten und ungezählten potenziellen Formen. Wörterbücher wie Duden bieten 100.000-150.000, Korpusse wie DWDS verdoppeln das durch Komposita und Spezialisierungen. Praktisch relevant: Die 50.000 häufigsten decken 95 Prozent Alltagstexte. Zukünftig wächst der Bestand um 5.000-10.000 jährlich, getrieben von Digitalisierung und Globalisierung. Wer präzise quantifizieren will, greift zu Korpus-Tools – statische Zahlen täuschen nur. Das Deutsche bleibt nominal reich, produktiv und unerschöpflich.