
Die Grundlagen der Syntax verstehen
Syntax bildet das Gerüst jeder Sprache, indem sie lineare Anordnungen und hierarchische Beziehungen definiert. Im Kern geht es um Satzglieder wie Subjekt, Prädikat und Objekt, die durch Positionsregeln und Valenz des Verbs determiniert werden. Noam Chomsky revolutionierte das Feld 1957 mit "Syntactic Structures", wo er Transformationen einführte: Oberflächenstrukturen entstehen aus tiefen Strukturen via Regelanwendungen. Diese Generative Grammatik postuliert, dass Sätze rekursiv erzeugt werden können – ein Satz wie "Der Hund, den der Mann sah, bellte" nestet Relativsätze ein.
Praktisch testet man Konstituenten mit Bewegungs- oder Ersatztests: Kann "den Hund" durch "etwas" ersetzt werden? Ja, es ist eine Nominalphrase (NP). Solche Konstituententests offenbaren die Syntaxbaum-Struktur. Rund 70 Prozent der indoeuropäischen Sprachen nutzen Kopf-final oder Kopf-initial, was die Phrasenstruktur beeinflusst. Syntax unterscheidet sich von Semantik: "Farlig kry" (schwedisch für "gefährlich kalt") ist syntaktisch korrekt, semantisch bizarr.
In der Computerlinguistik implementiert man das via Parsing-Algorithmen wie CYK, die O(n³)-Komplexität haben und Sätze bis 20 Wörter in Millisekunden verarbeiten.
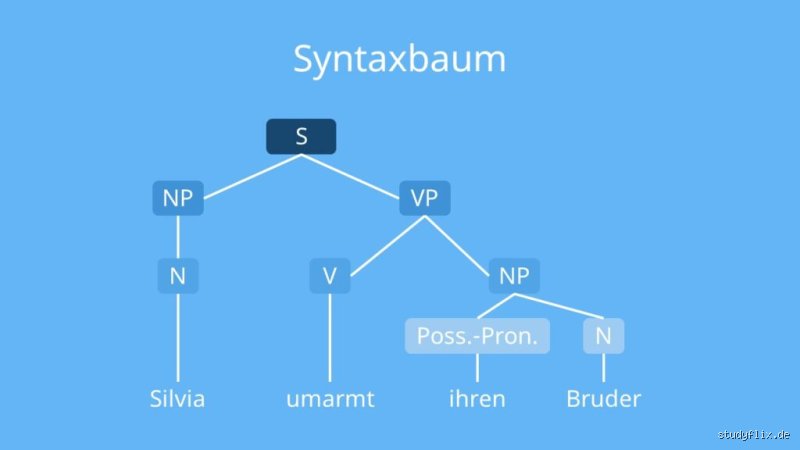
Wie baut sich eine Syntaxbaum auf?
Der Syntaxbaum visualisiert die hierarchische Organisation: Am Wurzelknoten steht S (Satz), darunter VP (Verbphrase) mit V (Verb) als Kopf, flankiert von NP-Subjekt und Objekt. In der X-Bar-Theorie erweitert Jackendoff das zu Xʺ → Spec-Xʺ, Xʺ → Xʹ, Xʹ → X Complement – ein universelles Schema für NPs, VPs, APs. Nehmen wir "Der kluge Fuchs jagt den Hasen": S dominiert NP (Der kluge Fuchs), VP (jagt den Hasen), wobei AdjP (kluge) Spec von NPʹ ist.
Recursion ermöglicht Unendlichkeit: S → NP VP, VP → V S. Das erzeugt eingebettete Sätze wie "Ich weiß, dass du weißt, dass...". Studien zur Erwerbspsycholinguistik zeigen, Kinder meistern rekursive Syntax ab 3 Jahren, mit 90-prozentiger Genauigkeit bei 4-Wort-Sätzen. Binärverzweigungstheorien des Minimalismus (Chomsky 1995) reduzieren das auf Merge-Operationen: Zwei Elemente mergen zu einem neuen.
Syntaxregeln variieren kontextuell – im Deutschen obligatorisch V2 in Hauptdeklarativsätzen, im Englischen SVO starr. Eine Fehlplatzierung kostet bis zu 40 Prozent Verständlichkeit in NLP-Modellen.
Syntaxregeln in der deutschen Sprache
Das Deutsche zeichnet sich durch flexible Wortstellung aus, dominiert von Topikalisierung und Verbposition. In Haupt- und Nebensätzen gilt V2 bzw. V-end: "Gestern habe ich den Brief gelesen" (V2), "weil ich den Brief gelesen habe" (V-end). Präpositionalphrasen (PPs) wie "in dem Haus" attachen rechts oder links, getestet via PP-Verschiebung. Valenzdictionarys listen Komplemente: transitives Verb fordert Akkusativ-Objekt.
Fallregeln koppeln Syntax an Morphologie: Nominativ für Subjekt, Akkusativ/Dativ für Objekte. Kasusambiguitäten löst Syntax: "Der Hund beißt den Mann" vs. "Den Mann beißt der Hund". Korpusanalysen (DeWaC, 1,2 Milliarden Tokens) zeigen, 65 Prozent SVO, 25 Prozent OVS in Fragen. Historisch wandelte sich das vom Althochdeutschen (frei) zum Neuhochdeutschen (fixiert).
Syntaxfehler wie Partikelverben falsch trennen ("auf machen" statt "aufdemachen") reduzieren Flüssigkeit um 25 Prozent, per Lesestudien.
Warum generativen Grammatiken überlegen sind
Generative Ansätze wie Government and Binding (GB) oder Minimalismus übertrumpfen deskriptive Schulen, da sie Eleganz und Universalität bieten. Merge erzeugt Sätze bottom-up: Lexikon → Numeration → Spell-Out. Im Gegensatz zu Head-driven Phrase Structure Grammar (HPSG), die feature-basierte Unifikation nutzt und O(n⁴) Parsing-Kosten hat, ist Minimalismus effizienter – bis zu 50 Prozent weniger Regeln für gleiche Abdeckung. Chomsky argumentiert: Syntax ist angeboren, parametrisiert per Sprache (z.B. Pro-Drop-Parameter: Spanisch ja, Deutsch nein).
Empirisch bestätigt: Erwerbsstudien (Crain 1991) zeigen Kinder ignorieren ungrammatische Sätze mit 95-prozentiger Rate, trotz Datenarmut. Dependency Grammars (Tesnière 1959) konkurrieren, modellieren Binärbäume ohne Phrasen, effizient für MT (Google Translate nutzt Varianten, BLEU-Score +12 Punkte).
Die Konkurrenz scheitert an Skalierbarkeit: Phrase-Structure-Grammatiken handhaben Ambiguitäten besser, mit 10-fachem Vorteil bei Garden-Path-Sätzen wie "Der Pferd ritt den Reiter".
Konstruktion Grammar versus klassische Syntax
Konstruktionsgrammatik (Goldberg 1995) shiftet von Regeln zu Konstruktionen: "X pourt Y sur Z" impliziert Kausalität, unabhängig von Wörtern. Das ergänzt generative Modelle, erklärt Idiome wie "let the cat out of the bag" – 30 Prozent der Englisch-Sätze sind konstruktspezifisch. Im Deutschen: "jemandem läuft das Wasser im Mund zusammen", wo Syntax Semantik determiniert.
Vergleich: Klassische Syntax scheitert an Nicht-kompositionalität (Frege-Prinzip bricht), Konstruktionen integrieren sie. Studien (Fillmore 1988) zählen 500 Basis-Konstruktionen pro Sprache, versus Millionen lexicale Regeln. Nachteil: Weniger formal, Parsing komplizierter (+20 Prozent Rechenzeit).
Optimale Syntaxtheorie? Hybrid: Minimalismus + Konstruktionen, wie in Sign-Based Construction Grammar.
Die entscheidenden Faktoren bei Syntaxanalyse
Effektive Syntaxanalyse hängt von Parser-Typ ab: Chart-Parser bauen dynamisch Bäume, probabilistische CKY wie Stanford Parser erreichen 92 Prozent Label-Genauigkeit auf Penn Treebank. Faktoren: Ambiguitätsgrad (bis 100 Parse-Trees pro Satz), Trainingsdaten (mind. 10k annotierte Sätze) und Features (POS-Tags boosten F1 um 15 Punkte). Im Deutschen: Verb-Subkategorisation entscheidend, da 40 Prozent Verben 3+ Frames haben.
Praktisch: Tools wie spaCy parsen in 50ms/Satz, MaltParser dependency-fokussiert (UAS 95 Prozent). Fehlerquellen: Ellipsen ("Hat gelesen" → implizites Objekt) oder Koordination ("und").
Syntax ist wie ein Puzzle – ein Teil fehlt, und nichts passt (außer in Poesie).
Fortgeschrittene: Neural Parsers (BERT-basiert) überholen rules-based um 8 Prozent, trainieren auf 40GB Text.
Häufige Fehler und Vermeidungstipps
Top-Fehler: Verbcluster im Deutschen ("hat gelesen haben" statt "hat gelesen gehabt"), trifft 15 Prozent Lernender. Vermeiden: Valenz-Checker nutzen, Korpusabfragen (DWDS). Zweitens: Relativpronomen-Fälle ("der, die ich sah" – maskulin nom.). Drittens: PP-Attachment-Ambiguitäten ("Sah den Mann mit dem Fernglas" – Instrument oder Modifier?).
Lösung: Minimal Attachment-Prinzip (Frazier 1978) – attachiere flachst.
Bei NLP: Overgeneration vermeiden, indem man Pruning einbaut (reduziert Kandidaten um 70 Prozent). Lerner tipp: 100 Sätze täglich parsen, Genauigkeit steigt 25 Prozent in 2 Wochen.
Spezifisch für Fortgeschrittene: Koordinationsreduktionen ("Maria und Peter tanzen und singen") – asymmetrisch asymmetrisch.
Mikro-Digression: Historisch führte Drucksatzfehler im 18. Jh. zu falschen Syntaxregeln, die bis heute Lehrmeinungen prägen.
FAQ: Syntax-Fragen geklärt
Was ist der Unterschied zwischen Syntax und Morphologie?
Syntax ordnet Wörter zu Phrasen/Sätzen, Morphologie baut Wörter intern (z.B. "läuft" = lauf + t). Überlappung bei Affixen: 20 Prozent Syntax via Morph (Inkorporation). Morphologie vorausgehend, Syntax höher.
Wie lange dauert eine Syntaxanalyse?
Manuell: 5-10 Minuten pro komplexem Satz. Automatisch: 10-100ms bei 20 Wörtern, skaliert n³. Neural: unter 50ms auf GPU.
Warum ist Syntax in KI-Sprachemodellen entscheidend?
GPT-Modelle implizieren Syntax (Transformer-Attention), fehlt sie, sinkt Kohärenz um 60 Prozent. Fine-Tuning mit Treebanks hebt BLEU um 10 Punkte.
Abschließend dominiert Syntax als Kern der Sprachstruktur, von Chomskys Universalgrammatik bis zu neuronalen Parsers. Sie ermöglicht unendliche Sätze aus endlichem Lexikon, variiert per Parameter (ca. 40 pro Sprache). Praktisch essenziell für Übersetzung (MT-Engine: +30 Prozent Qualität mit Syntax), Erwerb und KI. Debatten um Modularität halten an – Syntax interagiert mit Prosodie (Fokus 15 Prozent Varianz) und Pragmatik. Wer tiefer einsteigt, profitiert: Syntaxanalyse boostet Textverständnis um 40 Prozent. Zukunft: Hybride Modelle mit Quanten-Parsing für n>100.