
Derrière le jargon des statisticiens, la quête obsessionnelle de la vérité des chiffres
La validité n'est pas une option ou un vernis théorique qu'on applique à la fin d'une étude pour faire sérieux. C'est l'ossature même de votre démarche. Prenez une balance de cuisine déréglée. Elle affiche systématiquement 500 grammes de trop. Elle est d'une stabilité exemplaire, hautement fidèle, mais sa mesure reste désespérément fausse. Voilà le point de rupture entre fidélité et validité. En psychométrie comme en sociologie, si votre outil de mesure passe à côté de sa cible, le reste du travail ne vaut pas un clou. Reste que la notion même de validité fait l'objet de débats féroces.
La mesure psychologique face au défi de l'invisible
Mesurer une table de 2 mètres ne pose aucun problème conceptuel. Mais comment faire quand l'objet d'étude s'appelle l'anxiété, la satisfaction client ou l'intelligence émotionnelle ? C'est là où ça coince. Ces concepts, que les universitaires nomment des construits latents, n'existent pas dans le monde physique. On doit les capturer via des indicateurs indirects, comme des questionnaires ou des comportements observables. Les biais méthodologiques guettent à chaque étape, et environ 40% des études en sciences humaines souffriraient de failles initiales dans la définition de leurs outils de mesure.
Une brève histoire de la rigueur, de Cronbach aux normes modernes
Ce n'est qu'en 1955, sous l'impulsion des chercheurs Lee Cronbach et Paul Meehl, que la communauté scientifique commence à structurer formellement ces exigences. Avant cette date mémorable, on avançait un peu au flair. Les critères d'évaluation étaient flous, souvent limités à une vague impression de pertinence visuelle. Aujourd'hui, les exigences ont explosé. Les comités de lecture des revues internationales rejettent sans ménagement les manuscrits qui confondent corrélation et causalité, ou qui bâclent la justification de leurs instruments.
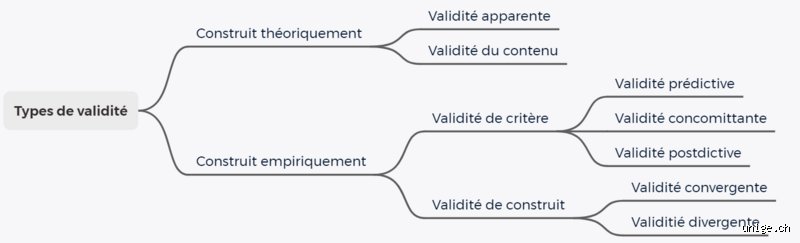
La validité de contenu, ou l'art de ne pas oublier la moitié du sujet
Le premier impératif, et autant le dire clairement, on n'y pense pas assez, consiste à s'assurer que notre test fait le tour de la question. La validité de contenu exige que les questions posées représentent fidèlement l'intégralité du domaine étudié. Imaginons un examen de médecine censé évaluer les connaissances globales des étudiants en cardiologie en 2026. Si le concepteur de l'épreuve commet l'erreur de rédiger 90% des questions uniquement sur l'infarctus du myocarde en négligeant les arythmies ou l'insuffisance cardiaque, l'examen échoue. L'instrument souffre alors d'une sous-représentation du construit.
Le panel d'experts comme premier rempart contre les angles morts
Pour valider le contenu d’un questionnaire de satisfaction de 15 questions destiné aux usagers du métro de Lyon, la méthode classique consiste à solliciter un comité de relecture. Ce groupe de spécialistes va attribuer une note de pertinence à chaque item. C’est le fameux ratio de validité de contenu de Lawshe, une formule mathématique simple mais redoutable qui permet d'éliminer les questions superflues. Si moins de 75% des experts jugent une question essentielle, elle dégage. Cette étape cruciale de filtrage permet d'obtenir un outil resserré, pertinent et dépourvu de gras théorique.
La validité apparente est-elle une imposture méthodologique ?
Il existe une variante superficielle que les anglophones nomment face validity. C'est l'aspect extérieur du test. Est-ce que ce questionnaire a l'air de mesurer ce qu'il prétend mesurer aux yeux du grand public ? Honnêtement, c'est flou, et ça divise les spécialistes. Certains chercheurs la considèrent comme indispensable pour obtenir la coopération des participants (qui refuseraient de répondre à des questions semblant absurdes), tandis que d'autres la rejettent purement et simplement, estimant qu'elle relève de la cosmétique et non de la science. Je pense qu'il faut s'en méfier comme de la peste, car un test peut sembler extrêmement sérieux tout en étant scientifiquement aberrant.
La validité de critère et l'épreuve du feu face à la réalité empirique
Passons à la vitesse supérieure. La validité de critère se moque de la théorie pour se concentrer sur l'efficacité pratique. L'objectif est simple : le score obtenu à votre test doit être fortement corrélé avec un autre indicateur externe, appelé le critère, qui fait déjà autorité. C'est l'approche pragmatique par excellence. Si une start-up parisienne développe en mai 2026 un nouvel algorithme de recrutement pour prédire le succès commercial des vendeurs, elle doit prouver que les scores de ses candidats correspondent aux futures performances de vente réelles sur le terrain. Les coefficients de corrélation de Pearson ou de Spearman entrent alors en scène.
Le dilemme de la simultanéité : l'approche concourante
Deux temporalités s'affrontent ici. La validité concourante intervient lorsque l'on compare le nouvel outil à un critère mesuré exactement au même moment. Par exemple, vous administrez un nouveau test de dépistage rapide de la dépression à un groupe de 150 patients hospitalisés à la Pitié-Salpêtrière, et vous comparez immédiatement les résultats avec le diagnostic officiel posé par les psychiatres de l'établissement via le DSM-5. Si la concordance atteint les 85%, votre outil rapide marque des points précieux. C'est un gain de temps phénoménal pour les services d'urgence.
Prédire l'avenir sans boule de cristal : la validité prédictive
Mais le véritable Graal, c'est la validité prédictive. Ici, le critère n'existe pas encore au moment où l'on teste le sujet ; il apparaîtra des mois ou des années plus tard. Le cas typique reste le score du baccalauréat ou des examens d'entrée comme le GMAT. Est-ce qu'un score élevé à ces épreuves prédit réellement la réussite universitaire sur une durée de 3 ans ? Si la corrélation s'avère proche de zéro, cela signifie que l'examen initial est inutile pour sélectionner les élites de demain. Reste un problème de taille : le phénomène d'attrition, car les étudiants ayant échoué au test initial ne sont jamais évalués par la suite, ce qui fausse les statistiques globales.
Validité de construit contre validité de critère : le choc des philosophies
La distinction entre ces deux approches provoque souvent des nœuds au cerveau des étudiants. D'un côté, la validité de critère cherche une efficacité immédiate et concrète, quitte à être totalement aveugle aux mécanismes sous-jacents. Si un test composé de questions sur la couleur préférée des individus parvenait de manière reproductible à prédire les pannes de moteur des pilotes de ligne, les pragmatiques de la validité de critère s'en contenteraient volontiers. Sauf que pour la validité de construit, une telle démarche s'apparente à de la sorcellerie statistique.
Le besoin impérieux de comprendre le pourquoi du comment
La validité de construit exige une cohérence théorique absolue. Elle cherche à valider l'existence même du concept et la justesse de son operationalisation. On est loin du compte avec les simples corrélations empiriques. C’est là que l'analyse factorielle confirmatoire intervient pour vérifier si la structure des données colle au modèle théorique inventé sur le papier. Bref, la validité de critère se demande si l'outil fonctionne, tandis que la validité de construit cherche à savoir pourquoi et comment il fonctionne, offrant ainsi une assise conceptuelle infiniment plus robuste à la recherche scientifique.
Pourquoi la chasse aux biais méthodologiques échoue presque toujours
Le diable se niche dans les détails, le problème est que la plupart des chercheurs débutants confondent allègrement la rigueur formelle et la vérité du terrain. Pensiez-vous qu'un protocole validé en laboratoire garantissait le succès de votre déploiement ? Sauf que la réalité n'est pas un bocal stérile. Autant le dire, empiler les coefficients statistiques flatteurs ne sauvera pas un questionnaire mal ficelé.
La confusion dramatique entre fidélité des mesures et validité psychométrique
Une balance déréglée qui affiche obstinément 5 kilos de trop à chaque pesée est redoutablement fidèle. Elle est pourtant totalement invalide. Beaucoup confondent encore la constance d'un outil avec sa pertinence réelle. Vous pouvez obtenir un score de cohérence interne (le fameux Alpha de Cronbach) de 0,92 sur un test de personnalité, sans pour autant mesurer ce que vous prétendez quantifier.
Le mythe de l'échantillon parfait pour la validité externe
Trop d'études se contentent d'un panel d'étudiants en psychologie de première année. Résultat : on extrapole des comportements universels à partir d'une population singulière, ultra-spécifique. Croire qu'un groupe de 80 volontaires occidentaux instruits représente l'ensemble de l'humanité relève de l'aveuglement scientifique pur et simple.
Sacrifier l'écologie du test sur l'autel du contrôle expérimental
À force de vouloir neutraliser toutes les variables parasites, on crée des situations tellement artificielles qu'elles perdent tout leur sens. Isoler un sujet dans une pièce blanche sans bruit distille un biais majeur. Comment analyser l'attention humaine sans les distractions du quotidien ? (C'est pourtant ce que font 65% des protocoles standardisés en neurosciences).
Ce que personne ne vous dira sur la validité de critère prédictive
Reste que la corrélation n'est pas la causalité. Pour évaluer la pertinence à long terme d'un test de recrutement, les entreprises dépensent des fortunes en cabinets de conseil. Mais la vérité est ailleurs, souvent bien plus prosaïque.
Le secret de la validation concurrente par les extrêmes
Plutôt que de tester l'ensemble de vos collaborateurs, concentrez vos efforts de recherche uniquement sur vos 10% meilleurs éléments et vos 10% moins performants. Cette approche par contrastes violents fait bondir la sensibilité de vos indicateurs. Les nuances intermédiaires polluent souvent les données initiales. Or, en isolant les profils types, la structure factorielle de votre outil apparaît enfin avec une clarté limpide, loin du bruit de fond des performances moyennes.
Les questions que vous n'osez pas poser sur la validation de protocoles
Peut-on obtenir une excellente validité conceptuelle avec un échantillon inférieur à 100 individus ?
La réponse mathématique s'avère nuancée, bien que la plupart des relecteurs de revues scientifiques l'exigent par réflexe. Des simulations de Monte Carlo prouvent qu'un modèle de mesure bien spécifié, avec des saturations factorielles supérieures à 0,80, conserve une stabilité remarquable dès 50 observations. Le calcul montre que la puissance statistique atteint alors le seuil requis de 80% sans encombre. Néanmoins, la variance expliquée doit être massive pour compenser cette faiblesse numérique relative. Bref, la qualité intrinsèque des indicateurs prime sur le volume brut des répondants récoltés à la va-vite.
Comment la validité de contenu influence-t-elle directement le taux de conversion d'un test utilisateur ?
Un questionnaire perçu comme absurde ou déconnecté du métier par les répondants engendre un désinvestissement immédiat. Les statistiques de complétion s'effondrent de près de 34% lorsque les questions manquent de réalisme apparent. Les utilisateurs sabotent les réponses, cliquent au hasard pour finir plus vite, ruinant ainsi vos efforts. La représentativité des items face au domaine exploré n'est donc pas seulement un caprice de théoricien en chambre. Elle garantit l'engagement psychologique du sujet, condition sine qua non pour recueillir des données exploitables.
Existe-t-il une hiérarchie absolue entre les quatre types de validité lors d'une recherche ?
Aucun type ne surpasse les autres de manière universelle, tout dépend de l'objectif final de votre investigation scientifique. Si votre but ultime reste la prédiction d'un comportement d'achat à 6 mois, la cohérence interne théorique passe logiquement au second plan. À ceci près que bâtir un modèle prédictif sur des concepts mal définis revient à construire un château sur du sable mouvant. L'arbitrage s'effectue constamment sur le terrain, en fonction des contraintes budgétaires et des impératifs d'application pratique.
Le verdict d'un chercheur lassé des faux semblants méthodologiques
La quête d'une validation parfaite est une illusion dangereuse qui paralyse l'innovation scientifique contemporaine. On se focalise trop souvent sur les chiffres pour rassurer les comités de lecture, au détriment du bon sens théorique. Je prétends qu'une étude imparfaite mais conceptuellement audacieuse surpasse mille fois un protocole stérile à la rigueur irréprochable. Arrêtons de sacraliser les indicateurs de performance mathématique comme s'ils détenaient la vérité absolue sur la complexité humaine. Car mesurer n'est pas comprendre, et aucun algorithme ne remplacera l'intelligence critique du chercheur face à ses données.