
Les fondamentaux de l'identification mathématique et analytique
L'identification d'une fonction ne relève pas du hasard mais d'une méthodologie rigoureuse basée sur l'observation des variations. Dans un contexte professionnel, que vous soyez analyste de données ou ingénieur, la première étape consiste à définir le domaine de définition. Une fonction n'existe que sur un intervalle précis. Par exemple, une fonction racine carrée ne peut traiter de valeurs négatives dans le champ des réels, ce qui limite immédiatement les possibilités de modélisation pour certains phénomènes physiques.
La distinction majeure s'opère souvent entre les fonctions algébriques (polynômes, fractions rationnelles) et les fonctions transcendantes (logarithmes, exponentielles, trigonométrie). Si votre jeu de données présente une périodicité stricte, comme les cycles de vente saisonniers sur 12 mois, vous devrez vous orienter vers des fonctions sinusoïdales. À l'inverse, une progression constante de 5 % par an pointe directement vers une structure exponentielle. La question n'est pas seulement de nommer la fonction, mais de comprendre la dynamique sous-jacente qui lie les variables.
Il est crucial de noter que 90 % des erreurs de modélisation proviennent d'une confusion entre une croissance polynomiale de degré élevé et une croissance exponentielle. Sur un échantillon court, les deux courbes peuvent sembler identiques. Cependant, dès que l'on projette les résultats à long terme, l'écart devient colossal. Une fonction de type x² progressera beaucoup moins vite qu'une fonction de type 2^x après seulement quelques itérations. Savoir quel type de fonction appliquer nécessite donc une vision prospective de l'évolution des données.
L'analyse graphique : le premier réflexe de l'expert
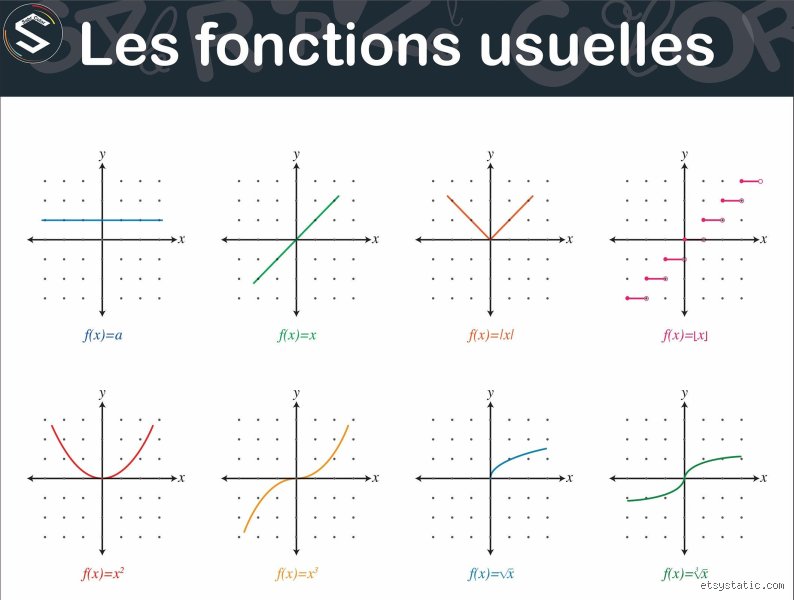
Le tracé d'un nuage de points est l'outil le plus puissant pour une identification rapide. Une droite qui passe par l'origine ne laisse aucun doute : c'est une fonction linéaire de type f(x) = ax. Si la droite est décalée sur l'axe des ordonnées, nous parlons d'une fonction affine. Ce sont les modèles les plus simples, mais aussi les plus robustes pour des prédictions à court terme où la volatilité est faible.
Lorsque la courbe change de direction, on entre dans le domaine des fonctions quadratiques ou polynomiales. Un seul point d'inflexion indique généralement un degré 2 (une parabole). Si la courbe ondule avec plusieurs sommets et creux, le degré du polynôme augmente. Je considère souvent que l'utilisation de polynômes au-delà du degré 3 est risquée en analyse de données réelle, car cela mène inévitablement à l'overfitting, un phénomène où le modèle colle trop aux bruits du passé sans pouvoir prédire l'avenir.
L'observation des asymptotes est également révélatrice. Si votre courbe semble plafonner à une valeur précise malgré l'augmentation de la variable X, vous êtes probablement face à une fonction logarithmique ou une fonction logistique. Ce type de comportement est typique de la saturation d'un marché ou de la limite de capacité d'un serveur informatique. Le coefficient de détermination R², souvent utilisé pour valider ces modèles, doit idéalement dépasser 0,95 pour garantir une fiabilité statistique acceptable dans les sciences appliquées.
Pourquoi la fonction linéaire reste le standard industriel dominant
La simplicité est une vertu en ingénierie. La fonction linéaire est privilégiée car son interprétation est immédiate : pour chaque unité supplémentaire de X, Y augmente de la valeur du coefficient directeur. Dans l'industrie, entre 70 % et 80 % des relations de cause à effet sont modélisées de manière linéaire, du moins localement. C'est le principe de l'approximation linéaire au voisinage d'un point.
Prenons l'exemple d'un coût de production. Si chaque pièce coûte 15 euros à produire avec un coût fixe de 5000 euros, la fonction f(x) = 15x + 5000 est d'une efficacité redoutable. Elle permet de calculer un seuil de rentabilité en quelques secondes. Cependant, cette linéarité a ses limites. Elle ignore les économies d'échelle ou, au contraire, la saturation des machines. C'est là que l'expert doit savoir quand abandonner le modèle linéaire pour introduire de la complexité.
Le danger réside dans l'aveuglement par la simplicité. Forcer une relation linéaire sur des données qui présentent une courbure naturelle fausse les prévisions de marge de plus de 20 % dans certains cas critiques. Il faut donc tester systématiquement la linéarité par une analyse des résidus. Si les résidus (l'écart entre le modèle et la réalité) forment un motif structuré (comme une courbe), alors le type de fonction choisi est incorrect. Les résidus doivent idéalement ressembler à un bruit blanc aléatoire.
Comment distinguer une croissance exponentielle d'une puissance ?
C'est ici que les erreurs coûtent le plus cher. Une fonction puissance (x^n) et une fonction exponentielle (e^x) n'obéissent pas aux mêmes lois fondamentales. Dans une fonction puissance, la base varie et l'exposant est fixe. Dans une fonction exponentielle, c'est l'inverse. Pour les différencier, l'astuce consiste à utiliser un repère semi-logarithmique. Si vos données forment une ligne droite sur ce type de graphique, vous avez affaire à une croissance exponentielle.
Les phénomènes biologiques, la propagation virale ou les intérêts composés suivent des lois exponentielles. Un taux de croissance de 3 % par jour peut paraître anodin, mais il double la valeur initiale en environ 23 jours. C'est la puissance du facteur multiplicatif. À l'opposé, les fonctions puissances se retrouvent souvent dans les lois physiques, comme la loi de la gravitation ou l'intensité sonore. Elles croissent rapidement, mais finissent toujours par être rattrapées par les exponentielles.
D'un point de vue pratique, si vous observez que le temps nécessaire pour doubler une valeur est constant (le fameux "temps de doublement"), ne cherchez plus : c'est une exponentielle. Si ce temps de doublement augmente à mesure que la valeur croît, vous êtes sans doute sur une fonction puissance ou polynomiale. Cette distinction est le socle de toute analyse financière sérieuse ou de toute étude de croissance démographique.
Les pièges des fonctions polynomiales complexes
Les fonctions polynomiales de type f(x) = ax^n + bx^(n-1)... sont les caméléons des mathématiques. Elles peuvent épouser presque n'importe quelle forme de nuage de points si l'on augmente suffisamment le degré n. C'est une tentation permanente pour l'analyste débutant qui souhaite obtenir un score de corrélation parfait. Pourtant, une fonction de degré 10 qui passe par tous les points de vos données historiques est souvent totalement inutile pour prédire le point suivant.
Le phénomène d'oscillation en bordure de domaine, connu sous le nom de phénomène de Runge, illustre bien ce problème. Plus vous augmentez le degré pour gagner en précision locale, plus vous risquez des comportements aberrants aux extrémités. En modélisation prédictive, la règle d'or est la parcimonie : choisissez toujours la fonction la plus simple qui explique de manière satisfaisante la variance des données.
Un autre piège réside dans l'extrapolation. Une fonction polynomiale peut s'envoler vers l'infini ou plonger vers des valeurs négatives de manière totalement irréaliste dès que l'on sort de la plage de données initiales. Pour savoir quel type de fonction utiliser, demandez-vous toujours : "Quel est le comportement limite de ce système ?". Si la réalité physique impose une borne supérieure, un polynôme n'est probablement pas le bon outil sur le long terme.
Le rôle critique des fonctions dans le développement logiciel
En programmation, savoir quel type de fonction utiliser prend une dimension différente, axée sur l'architecture et la performance. On ne parle plus seulement d'équations, mais de paradigmes. Une fonction pure est une fonction qui, pour les mêmes arguments, retournera toujours le même résultat sans effets de bord. C'est le pilier de la programmation fonctionnelle moderne (comme en Haskell ou avec certaines bibliothèques JavaScript comme Redux).
Choisir entre une fonction récursive et une fonction itérative est un dilemme classique. La récursion est élégante pour traiter des structures de données complexes comme les arbres ou les graphes, mais elle peut saturer la pile d'appels (stack overflow) si la profondeur est trop grande. Une fonction itérative (boucles for/while) est souvent plus performante en termes de consommation mémoire brute, avec un gain de rapidité pouvant atteindre 15 % à 30 % sur des traitements massifs de données.
Il existe aussi les fonctions anonymes, ou lambdas, utilisées pour des opérations rapides et éphémères. Elles sont idéales pour les filtres ou les transformations de listes. Cependant, l'abus de fonctions anonymes rend le code difficile à déboguer. Un développeur expert préférera une fonction nommée claire pour toute logique dépassant deux lignes de code. La lisibilité prime sur la concision, car le coût de maintenance d'un logiciel représente souvent 80 % de son coût total de possession.
Comment choisir la bonne fonction selon le contexte métier ?
Le choix n'est pas qu'une affaire de chiffres, c'est une affaire de compréhension métier. Dans le marketing, on utilise massivement la fonction logistique pour modéliser la probabilité de conversion d'un client. Pourquoi ? Parce qu'elle produit un résultat compris entre 0 et 1, ce qui correspond parfaitement à une probabilité. Utiliser une fonction linéaire ici n'aurait aucun sens, car elle pourrait prédire une probabilité de 120 %, ce qui est physiquement impossible.
Dans le domaine de la logistique et de la chaîne d'approvisionnement, on rencontre souvent des fonctions en escalier. Le prix du transport ne change pas pour chaque gramme supplémentaire, mais par tranches de poids (paliers de 5kg, 10kg, etc.). Ignorer cette nature discontinue de la fonction conduit à des erreurs d'optimisation de stock majeures. Savoir quel type de fonction choisir nécessite donc d'interroger les contraintes réelles du terrain avant de toucher à sa calculatrice ou à son IDE.
Enfin, dans le secteur de la finance de marché, les fonctions stochastiques intègrent une part d'aléa. On ne cherche pas une valeur exacte, mais une espérance et une variance. Le modèle de Black-Scholes pour le prix des options est un mélange complexe de fonctions exponentielles et de lois normales. Ici, la complexité est justifiée par la nature intrinsèquement incertaine des marchés financiers mondiaux.
FAQ : Résoudre les doutes fréquents sur les types de fonctions
Comment savoir si une fonction est croissante ou décroissante sans graphique ?
La méthode la plus fiable consiste à calculer la dérivée première de la fonction. Si la dérivée f'(x) est positive sur un intervalle donné, la fonction est croissante. Si elle est négative, elle est décroissante. Pour les fonctions simples comme les fonctions affines f(x) = ax + b, il suffit de regarder le signe du coefficient 'a'. Un coefficient positif indique une pente ascendante immédiate.
Quelle est la différence entre une fonction discrète et une fonction continue ?
Une fonction continue peut être tracée sans lever le crayon ; elle possède une valeur pour chaque point de son intervalle. Une fonction discrète ne possède des valeurs que pour des points isolés (souvent des nombres entiers). En informatique, presque toutes les fonctions sont techniquement discrètes à cause de la précision binaire, mais on les traite comme continues pour les calculs de tendances globales.
Pourquoi utiliser une fonction logarithmique plutôt qu'une racine carrée ?
Bien que les deux courbes se ressemblent par leur croissance ralentie, la fonction logarithmique est utilisée pour compresser des échelles de données très vastes (comme les décibels ou le pH). La racine carrée est plus fréquente dans les relations géométriques ou physiques (vitesse vs énergie cinétique). Le choix dépend de la loi physique ou économique que vous essayez de respecter scrupuleusement.
Conclusion sur la sélection stratégique des fonctions
Maîtriser l'art de savoir quel type de fonction appliquer à un problème donné est une compétence qui sépare l'exécutant de l'expert. Que ce soit par l'analyse graphique, l'étude des taux de variation ou la compréhension des contraintes métier, le choix doit toujours être guidé par un équilibre entre précision et simplicité. Rappelez-vous qu'un modèle n'est qu'une représentation simplifiée de la réalité. En privilégiant les fonctions robustes comme les modèles linéaires ou logistiques, et en évitant les pièges de la sur-complexité polynomiale, vous garantissez des analyses fiables et actionnables. La validation par les tests statistiques et l'observation des résidus reste l'ultime rempart contre les erreurs d'interprétation qui pourraient fausser vos décisions stratégiques.